I recently resolved a rather odd issue in my home lab. I don’t fully understand how the symptoms and solution line up, but am writing this article for my future self… if the issue returns I’ll at least have notes on the previous steps. If you end up finding this article from a search, please feel free to leave a comment, I’d be curious to know if you were able to resolve a similar issue.
A couple of months ago, I wanted to clean up some unused connections to a physical switch (tp-link JetStream T1600G-28TS 24-Port Gigabit Smart Switch with 4 SFP Slots). This is an access switch for some gigabit interfaces, has several VLANs configured on it, and does some light static routing of locally attached interfaces. As part of this cleanup, I wanted to reconfigure a few switch ports so that devices with dual connections plugged in next to each other and the unused ports on the switch were contiguous. Not super important but figured it would be an easy cleanup task & free ports would be easier to see in the future. For some reason however, I couldn’t reach the web management interface of the switch. I tried to ping the management interface, but that failed as well. I then tried to ping some of the default gateways for the locally attached interfaces this device was using for routing, but those failed to respond as well. This was odd as the switch was successfully routing & connected devices were communicating fine.
As an initial troubleshooting step, I decided to simply power cycle the switch, assuming that some management functionally was degraded. The switch came back online and devices attached to it were working as expected, however I still wasn’t able to manage/ping the switch. I assumed that the switch may have failed but wanted to troubleshoot a bit more. I thought perhaps one of the devices physically connected to the switch could have been the cause, so one at a time I physically disconnected active adapters, waited a few seconds and when the switch still wasn’t accessible, reconnected the cable. This made me think that the issue wasn’t a specific NIC, but maybe an attached device/host (which may have had a pair/team of network adapters on the switch) was causing the problem. I set out to power down all attached equipment, disconnect all devices, power cycle the switch, and confirm that the switch could be managed/pinged with only one management uplink attached.
While doing the power down process I had a continuous ping of the physical switch management address running in the background. As soon as a specific ESXi host was shutdown, the switch started responding to ping. I made a note of this host (a Dell Precision 7920 named core-esxi-34), but continued powering down everything in the lab, so that I could power it back on one item at a time to see when/if the problem returned. I fully expected turning on core-esxi-34 was going to cause the problem to return… but it did not. I powered on some VMs in the lab & did other testing, but the problem seemed to have cleared up. Thinking this was a one-time issue, solved by a reboot, I went ahead and reconfigured switch ports, moved devices, and completed the physical switch cleanup exercise. Not as easy to complete as I had originally guessed, but complete none the less.
I wanted to keep an eye on the situation, so the next day I tried to ping the switch again, but the symptoms had returned — I was no longer able to ping the physical switch management interface. I decided to start troubleshooting from the ESXi host that was noted during the earlier cleanup. I looked through a few logs and found a lot of entries in /var/log/vmkernel.log. These entries appeared to be SCSI/disk related, and not the network issue at hand, but I made note of them anyway as they were occurring about 10x per second and it was an issue that needed to be investigated.
2023-08-22T14:21:07.637Z cpu8:2097776)nvme_ScsiCommandInternal Failed Dsm RequestAfter seeing them spew by I caught one entry that looked a bit different:
2023-08-22T14:21:07.639Z cpu12:2097198)HPP: HppThrottleLogForDevice:1078: Error status H:0xc D:0x0 P:0x0 . from device t10.NVMe____Samsung_SSD_970_PRO_512GB_______________S469NF0K800877R_____00000001 repeated 10240 times, hppAction = 1But the 'Failed Dsm Request' entries surrounded this specific line. Since the logs were pointing at a specific storage device, I decided to check and see if any VMs were powered on stored on that device and found just one. I powered down the VM in question, but the log spew didn’t immediately stop. A few minutes later however, the continuous ping of the switch started replying. I checked the vmkernel.log again and noticed the Failed Dsm Request spew had stopped, followed by lines specifically related to that storage device:
2023-08-22T14:35:54.987Z cpu1:2097320)Vol3: 2128: Couldn't read volume header from 63d77d1e-8b63fe7c-04f6-6c2b59f038fc: Timeout
2023-08-22T14:35:54.987Z cpu1:2097320)WARNING: Vol3: 4371: Error closing the volume: . Eviction fails: No connection
2023-08-22T14:36:03.044Z cpu13:2100535 opID=55002bc9)World: 12077: VC opID sps-Main-42624-252-714962-a0-e0-14c9 maps to vmkernel opID 55002bc9
2023-08-22T14:36:03.044Z cpu13:2100535 opID=55002bc9)HBX: 6554: 'local-34_sam512gb-nvme': HB at offset 3211264 - Marking HB:
2023-08-22T14:36:03.044Z cpu13:2100535 opID=55002bc9) [HB state abcdef02 offset 3211264 gen 28113 stampUS 96099954819 uuid 64e3507b-6256ea04-091a-6c2b59f038fc jrnl <FB 15> drv 24.82 lockImpl 3 ip 192.168.127.34]
2023-08-22T14:36:03.044Z cpu13:2100535 opID=55002bc9)HBX: 6558: HB at 3211264 on vol 'local-34_sam512gb-nvme' replayHostHB: 0 replayHostHBgen: 0 replayHostUUID: (00000000-00000000-0000-000000000000).
2023-08-22T14:36:03.044Z cpu13:2100535 opID=55002bc9)HBX: 6673: 'local-34_sam512gb-nvme': HB at offset 3211264 - Marked HB:
2023-08-22T14:36:03.044Z cpu13:2100535 opID=55002bc9) [HB state abcdef04 offset 3211264 gen 28113 stampUS 96129744019 uuid 64e3507b-6256ea04-091a-6c2b59f038fc jrnl <FB 15> drv 24.82 lockImpl 3 ip 192.168.127.34]
2023-08-22T14:36:03.044Z cpu13:2100535 opID=55002bc9)FS3J: 4387: Replaying journal at <type 6 addr 15>, gen 28113
2023-08-22T14:36:03.046Z cpu13:2100535 opID=55002bc9)HBX: 4726: 1 stale HB slot(s) owned by me have been garbage collected on vol 'local-34_sam512gb-nvme'Unsure how the two issues could be related (a storage error from an ESXi host causing an issue with a physical network switch), I decided to try and move everything off this 512GB NVMe device, delete the VMFS, and not use if for some time and see if the issue returned. The next time I checked the issue had returned. Upon further investigation of the vmkernel.log I found a similar log entry, surrounded by the familiar Failed Dsm Request spew:
2023-08-25T12:00:24.916Z cpu1:2097186)HPP: HppThrottleLogForDevice:1078: Error status H:0xc D:0x0 P:0x0 . from device t10.NVMe____Samsung_SSD_970_PRO_1TB_________________S462NF0M611584W_____00000001 repeated 5120 times, hppAction = 1This is a different 1TB NVMe device in the host, which had a VMFS volume with running VMs on it. I wanted to see if this NVMe device had any firmware updates available, but I wasn’t able to find firmware for a 970 Pro device, only 970 EVO and 970 EVO Plus. For grins, I did boot the host to a USB device with these firmware updates & it confirmed that the update did not detect devices to update.
As I was looking at these two NVMe Disks, I did notice one thing that I thought was sort of strange — I had expected each device to have its own vmhba storage adapter, which is somewhat typical for NVMe. However, in my case, both of these devices were attached to vmhba2 per the following screenshot.
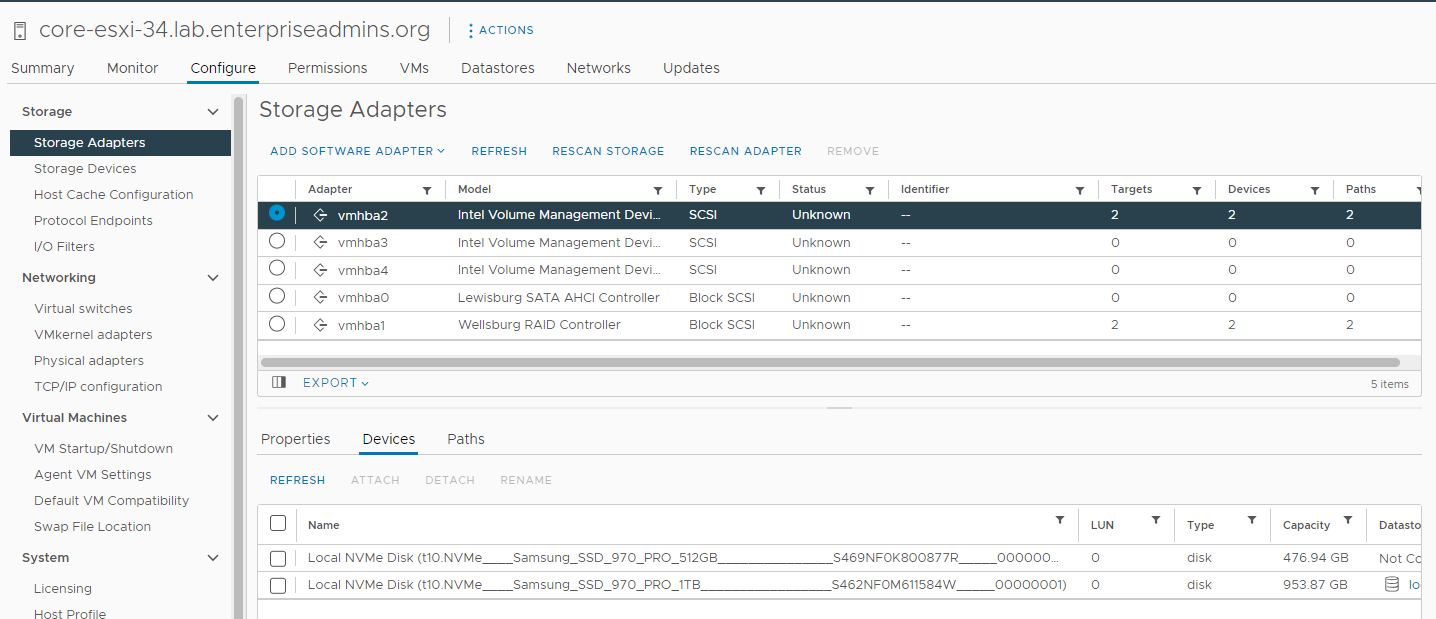
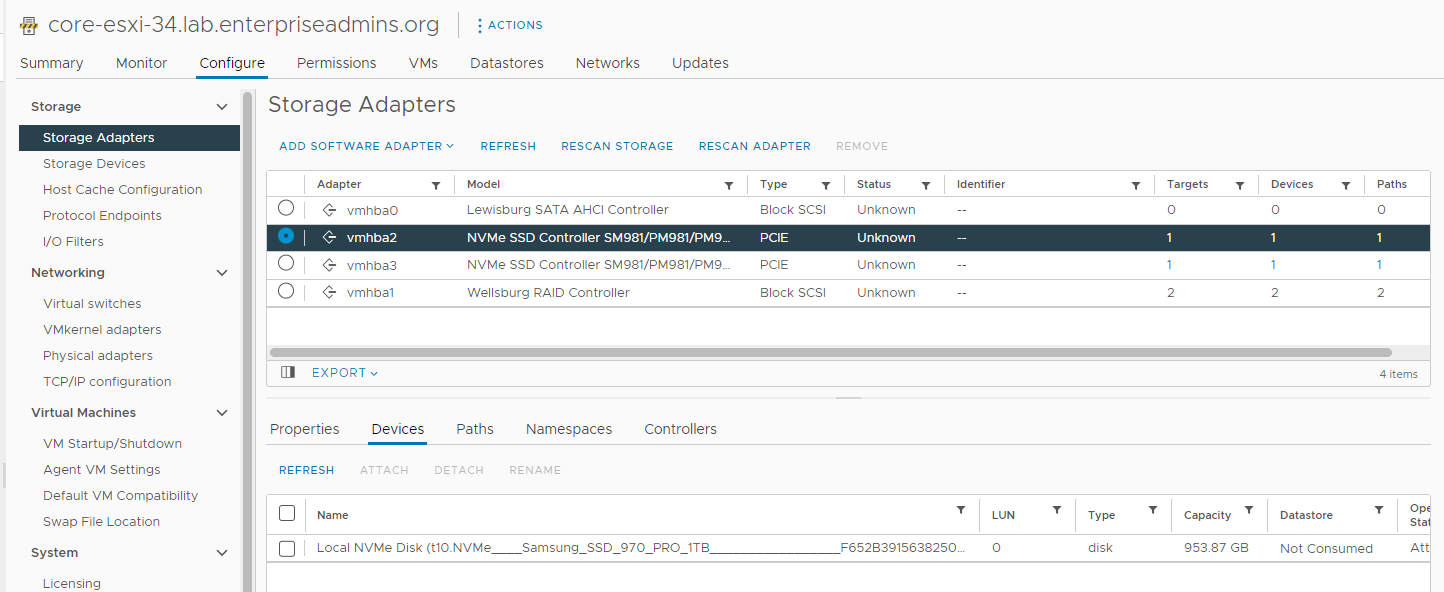
I did a bit of searching on the Intel Volume Management Device and realized that it could provide RAID1 for NVMe. With this particular setup however, these local NVMe devices have short term test VMs on them that I want to perform well, but don’t really care if the data is lost. As an aside, I checked after the fact and confirmed the host had a software package for Intel NVME Driver with VMD Technology (version 2.7.0.1157-2vmw.703.0.20.19193900) installed. I only mention it as it could be relevant and wanted to keep it for my notes as this issue may have been fixable using the VMD controller. I found an article (Precision 5820 Tower, Precision 7820 Tower, Precision 7920 Tower NVMe Drives Do Not Work in Legacy Mode | Dell US) which had some steps for disabling VMD via BIOS > Settings > System Configuration > Intel VMD Technology and deselecting / disabling all the options on that screen. I took this step, but when the host came back online, the local-34_sam1tb-nvme VMFS was inaccessible & it had a couple of VMs on it that I was in the middle of using. I backed out the change and when the host came back online the VMFS was accessible. I migrated the VMs on this datastore to other temporary storage and then reimplemented the changes. After disabling the Intel VMD, the system shows fewer vmhba devices, and each NVMe device is on its own SSD controller. The device type also changed from SCSI to PCIE as pictured below.
I created new VMFS volumes, one on each NVMe device, and moved some VMs back to them to generate IO. I’ve subsequently created new VMs, generated a lot of IO, deleted temporary VMs and generally put the devices through their paces. I have not seen the issue with the management address of the physical switch since. The problem used to return in a few hours/days, but this updated configuration has been running for over a week and has been stable.
Summary: I suspect that disabling Intel Volume Management Device (VMD) for these NVMe devices resolved this issue. However, it is possible there was some sort of VMFS corruption on the devices and deleting/recreating the filesystem was the fix. Additionally, I did not investigate the possibility of a newer/OEM driver for the Intel VMD controller. I wanted to capture these notes in this post; if the issue returns, I’ll I have an idea where to start troubleshooting next time.